
本記事は、2026年3月26日に開催したセミナー「【AIはなぜ「嘘」をつくのか?】データ分析の精度を劇的に変える「辞書登録」の重要性」の内容を記事にまとめたものです。
ChatGPTやGemini、Copilotといった生成AIの普及により、専門知識がなくても誰もがデータ分析にAIを使おうとする時代になりました。BigQueryなどにデータを溜め、「データさえあればAIが答えを出してくれる」という期待が広がっています。
ところが、いざAIに分析させてみると、現場では次のようなお悩みをよく耳にします。
- 思うような回答が返ってこない
- AIが計算した数字が、自社で集計した数字と合わない
- エラーが出て分析が止まってしまう
なぜ、最新のAIを使っても「求めている数字」が出せないのでしょうか。本セミナーでは、その根本原因が「辞書(データ定義)の欠如」にあることを、BigQuery上での実演を交えて解説しました。本記事ではその内容をレポートします。
・AIの回答精度を劇的に向上させる「辞書登録」の考え方と書き方
・自社で辞書登録を進めるときの優先順位と、つまずきやすい落とし穴
目次
登壇者紹介

株式会社メディックス マーケティングデザインユニット シニアテクニカルコンサルタント 鈴木 清蔵
2008年からメディックスにて、Adobe AnalyticsやGoogle アナリティクスの黎明期より、サイトにおけるKPI設計・実装・分析までを一貫して支援し、数多くの企業のマーケティング課題解決に貢献してきた。現在はその知見をGoogle Cloud領域へと広げ、データを統合するシステム基盤の構築から高度な分析、AI活用に至るまで、テクノロジーを起点としたデータドリブンな意思決定支援に取り組んでいる。
なぜ、最新のAIでも「求める数字」が出せないのか
生成AIの登場でデータ分析は急速に身近になりました。一方で、AIにデータをつなげられるようになっても「回答がズレる」「数字が合わない」という壁に多くの方がぶつかっています。この原因を一言でいえば、AIが参照すべき「辞書(データの定義)」が用意されていないからです。
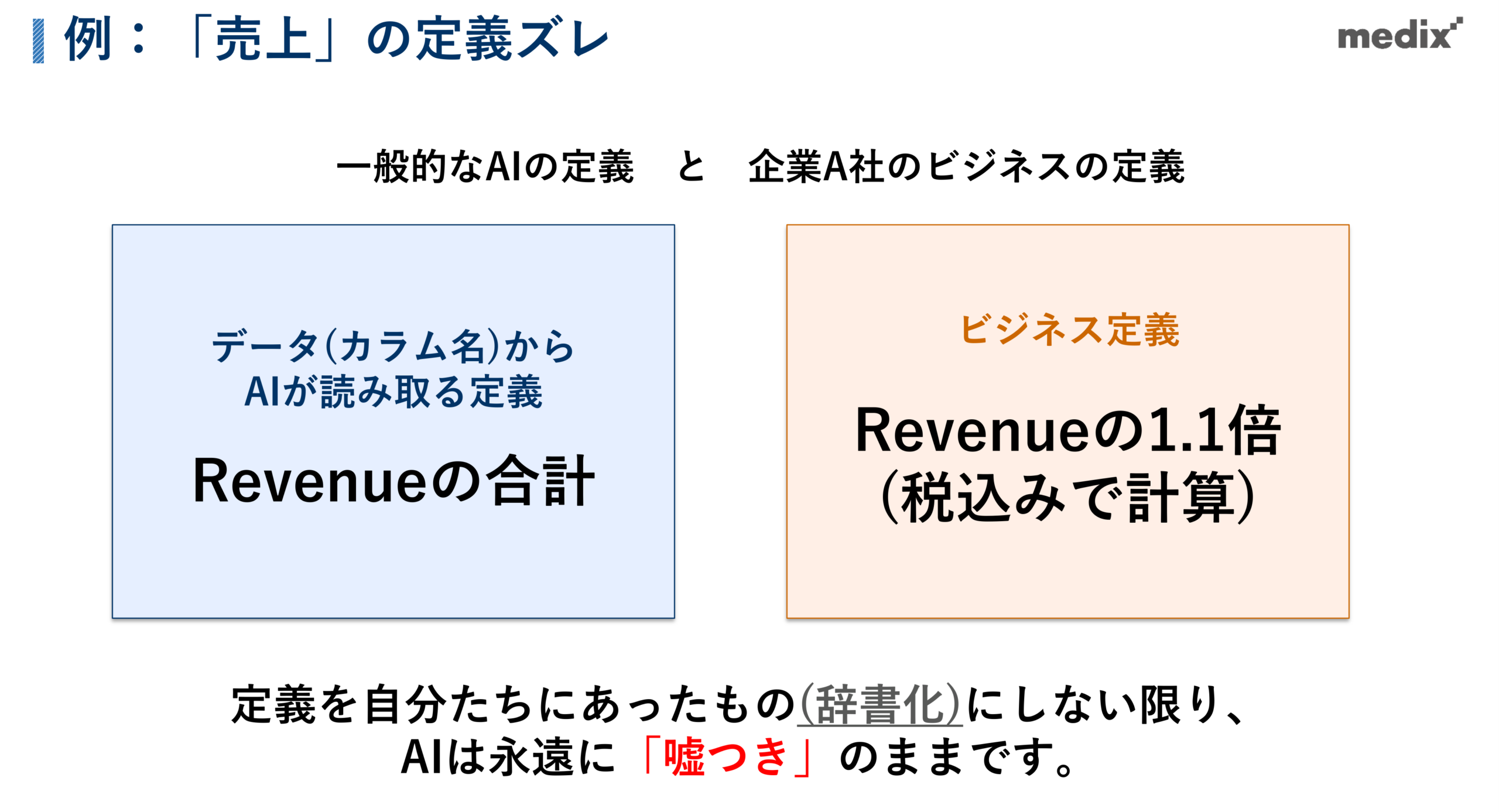
具体例で考えてみます。AIに「先月の売上は?」と尋ねると、AIは「1,000万円」と回答しました。しかし、自社で集計した実際の数字は「1,100万円」。なぜ100万円もずれてしまうのでしょうか。
理由は、AIは計算は得意でも「意味」を知らないからです。AIはWeb上に存在する一般論をもとに判断するため、会社独自の定義までは分かりません。例えば、売上を表すカラム「Revenue」があれば、AIはごく自然に「Revenueを合計すればよい」と解釈します。ところが、ある企業では売上を「Revenueの1.1倍(税込)」で見ていました。この企業独自のルールはWeb上のどこにも書かれていないため、AIには知りようがないのです。

つまり、定義を自分たちに合ったもの(辞書)にしない限り、AIは「一般論の正解」を返し続けます。結果として、自社にとっては「嘘つき」のように見えてしまうのです。
【実演】辞書あり・なしで、AIの回答はこう変わる
続いて、辞書(定義)を登録した場合としていない場合で、AIの回答が実際にどう変わるのかをBigQuery上で実演しました。用意したのは、中身はまったく同じデータでありながら、片方には説明(定義)を登録し、もう片方には何も登録していない2つのテーブルです。同じ質問をAIに投げて、結果を比べていきます。
実演①:売上の集計
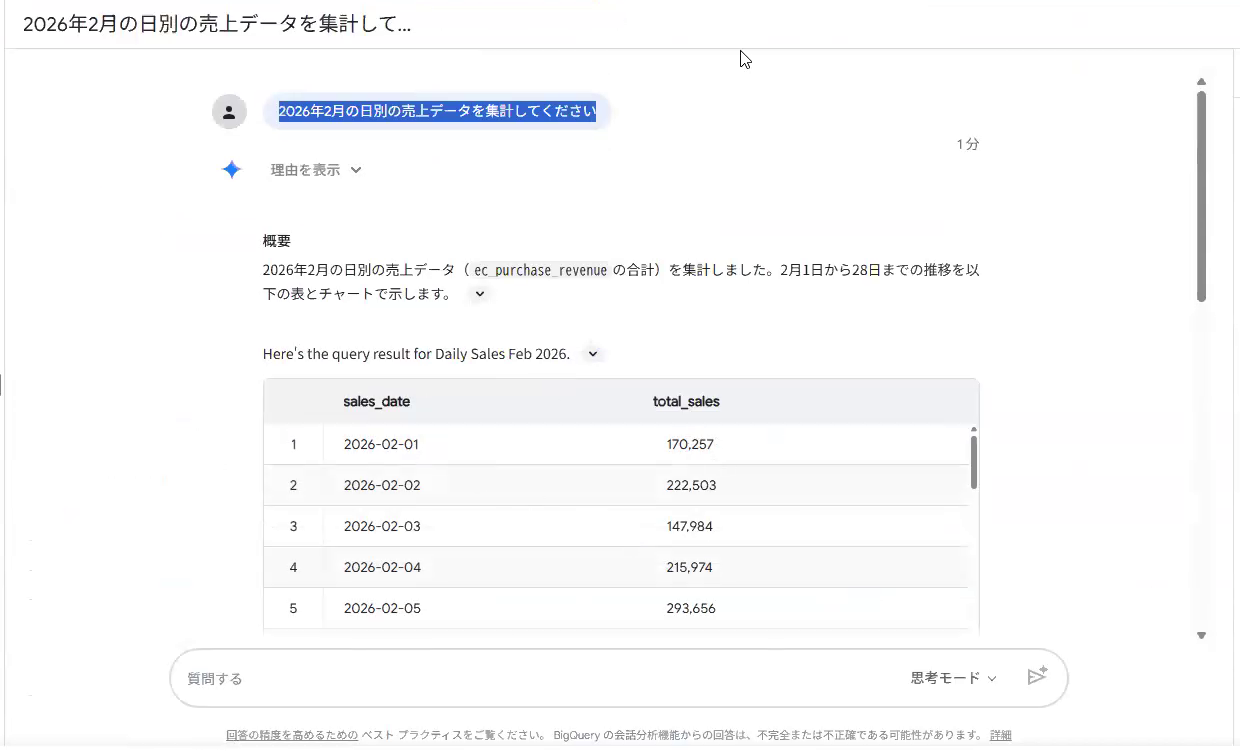
まず「2026年2月の日別の売上データを集計してください」と指示します。
2026年2月の日別の売上データを集計してください
定義を登録していないテーブルでは、AIはカラムの値をそのまま合計し、2月1日は170,257という数字を返しました。これは税抜のままの集計です。
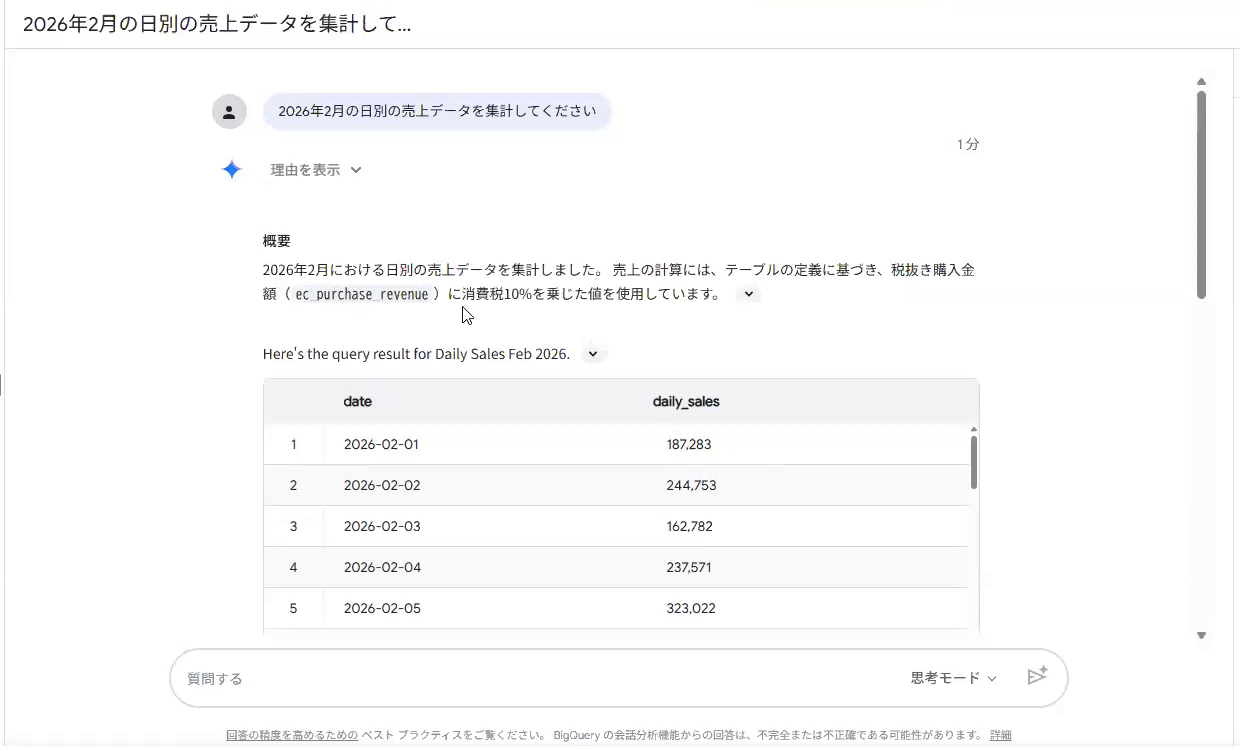
一方、テーブルの説明欄に「売上とは、税抜の購入金額に消費税10%を加えたもの」という定義と計算ロジックを登録しておくと、同じ質問でもAIは定義に従って税込で集計し、2月1日は187,283を返しました。たった一言、定義を書き加えるだけで回答が変わったことが分かります。
実演②:会員数の集計
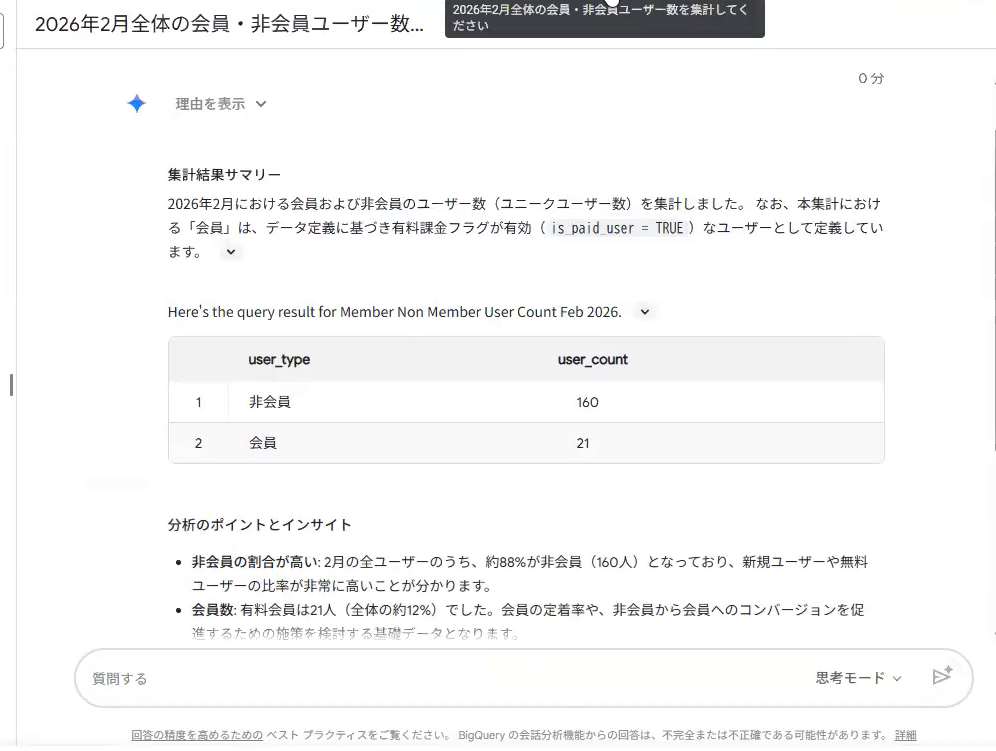
次に「会員数」を集計します。「会員」という言葉は、企業によって意味が大きく異なる代表例です。
定義を登録していないテーブルでは、AIは「会員=メルマガ登録者だろう」と勝手に推測し、メルマガ登録の有無で集計してしまいました。
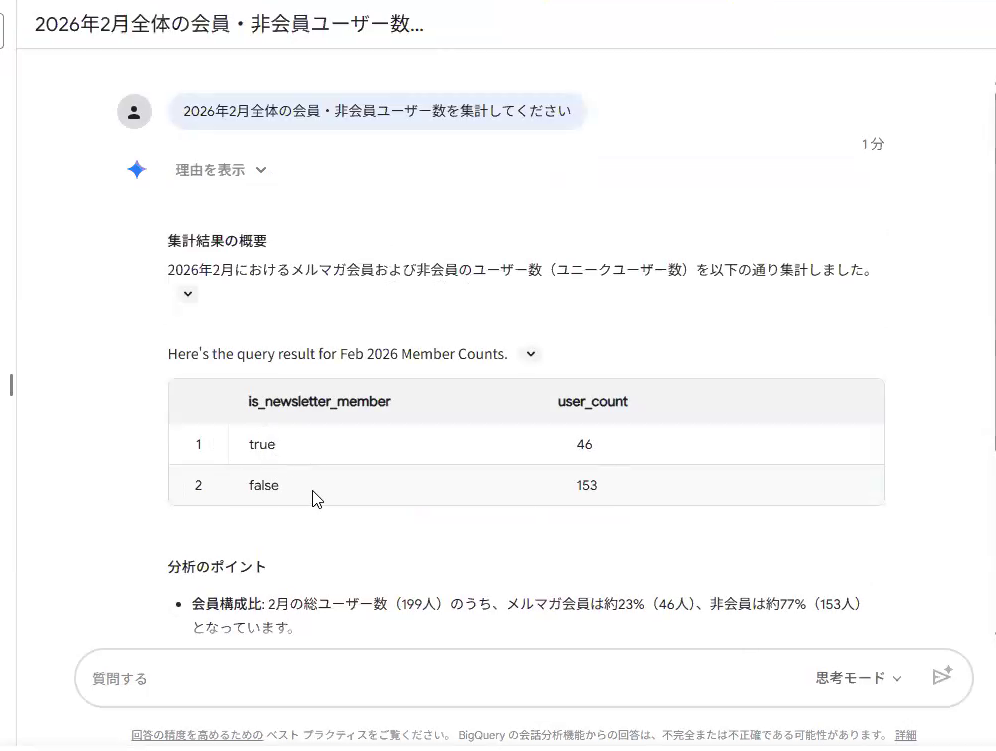
これに対し、「会員とは有料課金ユーザー(is_paid_userがtrue)である」と定義を登録しておくと、AIはその定義に沿って正しくカウントし、会員と非会員の数が変わりました。「会員」のように人によって意味が変わる言葉ほど、明確な定義が欠かせません。
仮にAIが間違えても、その都度「それは違う、こう計算して」と指摘すれば直せますが、そのやり取り自体が無駄な工数です。あらかじめ定義しておけば、誰が同じ質問をしても同じ答えが返るようになります。
では、どんな情報を登録すべきか
「定義が大事なのは分かったが、項目も切り口も膨大で、どこから手をつければよいのか」という声は当然出てきます。登録すべき情報を優先度で3段階に整理して紹介いたします。
| レベル | 対象 | 具体例とポイント |
|---|---|---|
| Lv.1(必須) | KGI・KPI指標 (経営・現場が追う数字) |
売上(税抜/税込、送料を含むか)、粗利(原価の定義)、CPA・ROAS・LTV・解約率など。ここがズレると意思決定を誤るため、最も定義揺れが起きやすく、最優先で固めるべき箇所。 |
| Lv.2(重要) | 主要な切り口 (分析軸・ディメンション) |
会員ランク、商品カテゴリ、流入チャネル(Web/アプリ/店舗)、新規/既存区分など。「会員ランク別の売上は?」のようにKPIを分解して原因を特定する際に必ず使う。 |
| Lv.3(任意) | マスタ・属性情報 | 都道府県、性別、年代、キャンペーン名など。深掘りで使うが、定義が自明なもの(性別など)は揺れにくいため後回しでよい。 |
まずはLv.1のKPI・KGIだけでも徹底的に定義する。それだけでもAIの回答精度は大きく改善します。AIの登場は、自社のKPI・KGIを改めて明確に言語化するよい機会だとも言えます。
やりがちな3つの落とし穴
辞書をつくる際に、特に注意したい3つの落とし穴も紹介します。
| 落とし穴 | 起きること | 対策 |
|---|---|---|
| 1. 「暗黙の了解」を書かない | 関係者なら言わなくても分かる「当たり前」を省いてしまう。例:「売上」とだけ書き、「キャンセル・返品を除く」「テスト注文を除く」を書かない。 | 「除外条件」こそ最優先で書く。「売上=受注金額 WHERE status != ‘cancelled’ AND user_type != ‘test’」のように条件まで明記する。 |
| 2. 「揺らぐ用語」を放置する | 社内で人によって意味が違う言葉をそのまま登録。例:「会員数」がマーケ部では無料会員を含み、営業部では有料課金ユーザーのみを指す。 | 修飾語をつけて区別する。曖昧な「会員数」は禁止し、「無料会員数」「有料会員数」「アクティブ会員数」と別々に定義する。 |
| 3. 「計算式」を書かない | 定性的な説明だけで、具体的なカラム名や計算ロジックを書かない。例:「粗利=売上から原価を引いた利益」だけだと、AIはどのカラムが原価か迷う。 | 物理カラム名と計算ロジックをセットで書く。例:「粗利=sales_amount − cost_amount。※cost_amountは移動平均法で算出した原価カラム」 |
辞書づくりは「翻訳」と「実装」の両輪
とはいえ、データがまだBigQueryに入っていない、バラバラの状態である、どれが重要な指標か整理できていない、という企業も少なくありません。そうした場合、ビジネスとシステムの橋渡しが必要となります。この橋渡しは2要素から構成されます。
1つ目が「翻訳」です。
アクセス解析をはじめ多様なデータを扱ってきた知見をもとに、マーケティング視点で「正しい定義」を言語化します(CPA・ROAS・LTVなどを、自社ではどう定義するか)。
2つ目が「実装」です。
定義に沿ってデータを入れ込み、使いやすいデータマートを設計し、表記ゆれ・欠損値・異常値をクレンジングして、AIが読み込める高品質なデータとして整備します。
定義書をつくっても、実際のデータが汚れていたり集計ロジックが誤っていたりすれば意味がありません。つまり、ビジネスルール(複雑な条件)を正確なクエリに落とし込み、分析の現場で本当に使えるデータマートとして作りきるという役割が必要となります。
質疑応答(抜粋)
Q. 全項目の定義は工数が膨大。どの項目を優先的に登録すべきですか?
最優先は、意思決定に直結するKPI・KGIです。改めて社内で「本当のKPI・KGIは何か」を明確に言語化することから始めるのがよいでしょう。Lv.1の指標を固めるだけでも、AIの回答精度は大きく変わります。
Q. 辞書登録で、AIの計算ミスやハルシネーションはどれくらい回避できますか?
定義のズレは劇的に減らせます。ただし、AIの特性上、100%なくすのは難しいのが実情です。だからこそ、メディックスでは、定義の文章化だけでなく、AIが読みやすい形にデータを整える部分も重要だと考えています。データをクレンジングし、計算しやすい形に整えておくことで、誤りが起きにくい環境をつくれます。
Q. BIツール(データポータルなど)と、今回のようなAI分析はどう使い分けるべきですか?
BIとAIは役割が異なります。KGI・KPIが決まっていて毎日見るような定点観測には、視覚的に分かりやすいBIのダッシュボードが向いています。一方で「今日はいつもと数字が違う」と気づいたとき、その原因を深掘りするのがAIです。BIで定点観測し、気になった点はAIに聞く。この使い分けが、スピード感の面でも最も効果的です。
まとめ
AIを活用したデータ分析には、正しいデータ定義(辞書)が欠かせません。そして、定義づくりには、ビジネスを理解して言語化する力と、それをデータに落とし込む実装力の両方が必要です。
辞書を整えれば、マーケターが「先月の売上は?」「会員別の傾向は?」と日常の言葉で尋ねるだけで、自社の定義に沿った正確な数字が返ってきます。システム部門への抽出依頼と手戻りのラリーから解放され、現場は本来の戦略立案や施策の実行に集中できるようになります。AIを「嘘つき」にしないために、まずは自社のKPIの定義を見直すことから始めてみてはいかがでしょうか。


